

Kafka로 채팅을 구현하기 앞서 Kafka에 대해서 공부하기 위해 Kafka를 간단하게 연동해보는 실습을 해보겠습니다.
Kafka 란?
파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 설계된 고성능 분산 이벤트 스트리밍 플랫폼이다.
pub/sub 모델의 메시지 큐 형태로 동작하며 분산환경에 특화되어있다.
- 큐잉 모델
- 브로커(서버) 안에 메시지 큐가 존재한다.
- producer는 큐로 메시지를 보내고, consumer가 큐에서 메시지를 추출한다.
- 하나의 큐에 여러개 컨슈머가 접근할 수 있어서 병렬 처리가 가능하다.
- 하나의 메시지는 하나의 Consumer에서만 처리된다.
- pub/sub 모델
- producer를 publisher, consumer를 subscriber로 명명한다.
- publisher가 subscriber에게 직접 메시지를 보내고 받는 것이 아닌, 브로커를 통해서 전달한다.
- publisher는 누가 수신하는지 알 수 없다.
- 브로커 내의 토픽이라는 카테고리에 등록한다.
- subscriber는 특정 토픽만을 선택해서 읽을 수 있고, 같은 토픽을 구독한 subscriber는 동일한 메시지를 받는다.
Kafka의 주요 특징
각 특징에 대한 설명은 따로 포스팅을 쓰겠다.
- 높은 처리량과 낮은 지연시간
- 높은 확장성
- 고가용성
- 내구성
- 개발 편의성
- 운영 및 관리 편의성
Kafka 용어
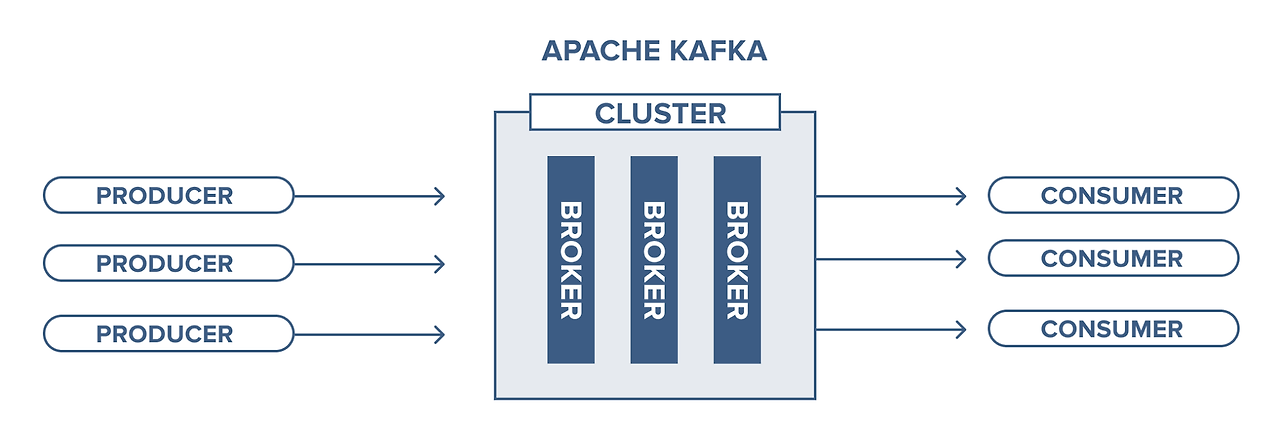
- Producer
- kafka에서 메시지를 생성하고, 해당 메시지를 카프카 클러스터에 전송하는 애플리케이션
- 한개, 혹은 여러개의 토픽으로 메시지를 보낼 수 있다.
- Consumer
- 카프카에서 메시지를 읽는 애플리케이션
- 한개, 혹은 여러개의 토픽에서 메시지를 가져올 수 있다.
- 파티션마다 한 컨슈머만 데이터를 가져갈 수 있다.
- broker
- 카프카 애플리케이션이 설치된 서버를 의미한다.
- 브로커를 추가하여 처리량 향상이 가능하다.
- zookeeper
- 브로커 health check 등 카프카 클러스터의 메타 데이터 관리 및 클러스터의 다양한 관리 작업을 수행한다.

- topic
- 카프카는 토픽이라는 곳에 데이터를 저장한다.
- 이메일 주소로 비유할 수 있다.
- 토픽의 이름은 카프카 내에서 고유하다.
- partition
- 토픽의 병렬처리를 위해 여러개의 파티션이라는 단위로 나뉜다.
- 카프카에서는 파티셔닝을 통해 단 하나의 토픽이라도 높은 처리량을 수행할 수 있다.
- 파티션 번호는 0부터 시작한다.
- 브로커 수 = 파티션 수를 맞추는 것이 성능에 좋다.
- 서비스 중에 파티션을 추가로 늘리는 것은 가능하지만 줄이는 것은 불가능하다. (토픽 삭제를 해야하므로 신중해야한다. 모니터링하면서 조절하는 것을 권장)
- offset
- 파티션의 메시지가 저장되는 위치
- 순차적으로 증가하는 숫자 (64비트의 정수)형태이다.
프로젝트
구성
springboot 3.3.2
java 17
docker 27.0.3
gradle dependencies
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.kafka:spring-kafka'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
도커로 kafka 실행 하기
docker 설치
https://docs.docker.com/desktop/install/mac-install/
Install Docker Desktop on Mac
Install Docker for Mac to get started. This guide covers system requirements, where to download, and instructions on how to install and update.
docs.docker.com
저는 맥 m3를 사용하고 있으므로 Docker Desktop for Mac with Apple silicon으로 설치하였습니다.
docker-compose.yml 작성
version: '3.8'
services:
zookeeper:
image: wurstmeister/zookeeper:latest
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:latest
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sockdocker-compose.yml 실행
docker-compose -f kafka-compose.yml up위 명령어를 실행하고 설치한 docker desktop에서 실행 중인지 확인할 수 있다.
(명령어로 확인 가능)
카프카 예제 코드 작성
KafkaConsumerConfig
@Configuration
@EnableKafka // Kafka 리스터 어노테이션 활성화, Kafka 리스너가 Spring 컨텍스트에서 작동하도록 한다.
public class KafkaConsumerConfig {
// Kafka Consumer를 생성하는 팩토리
@Bean
public ConsumerFactory<String, Object> consumerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(ConsumerConfig.GROUP_ID_CONFIG, "group_1");
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 오프셋을 찾을 수 없을 때 가장 최신의 메시지부터 읽기 시작하도록 설정
config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
// 아래 두줄 코드는 토픽에 대해서 auto commit으로 100초로 간격을 설정
// config.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
// config.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 100000);
return new DefaultKafkaConsumerFactory<>(config);
}
// Kafka 리스터 컨테이너 팩토리 정의, Kafka 리스너를 컨테이너화하여 실행
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Object> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}
KafkaProducerConfig
@Configuration
public class KafkaProducerConfig {
// Kafka producer를 생성하는 팩토리
@Bean
public ProducerFactory<String, Object> producerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(config);
}
// KafkaTemplate을 생성하여 Kafka 프로듀서를 사용하여 메시지를 보낼 수 있도록 한다.
@Bean
public KafkaTemplate<String, Object> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
KafkaProducerController
@RestController
@RequiredArgsConstructor
@RequestMapping("/kafka")
public class KafkaProducerController {
private final TestProducer testProducer;
@PostMapping("/sending")
public void create() {
testProducer.create();
}
}
TestProducer
@Component
@RequiredArgsConstructor
public class TestProducer {
private final KafkaTemplate<String, Object> kafkaTemplate;
public void create() {
kafkaTemplate.send("topic", "say hello~!!!!");
}
}
TestConsumer
@Component
public class TestConsumer {
@KafkaListener(topics = "topic", groupId = "group_1")
public void listen(String message) {
System.out.println("Received Messasge in group group_1: " + message);
}
}
테스트
저는 포트만 다르게 두개의 서버를 띄워놓고, 1개의 서버에는 위 코드 대로 groupId를 group_1로 했고, 다른 서버에는 group_2로 설정해서 테스트했습니다.
localhost 8080서버

localhost 8081 서버

추가로 8080 서버만 가동시키고 8081은 가동시키지 않은 상태에서 메시지를 보냈을 때
다시 8081서버를 가동시키면 보내지 못했던 메시지를 받게 된다. (Consumer Config에서 auto offset reset config 부분)
이는 Kafka의 메시지 영속성 때문인 것으로 보인다. 메시지를 브로커의 디스크에 영구적으로 저장하여 메시지가 토픽에 저장되면 해당 메시지는 구성된 보존 기간 동안 삭제되지 않고 저장한다. (위 프로젝트에서는 보존기간은 따로 설정하진 않았다.)
이로 인해 컨슈머가 메시지를 즉시 처리하지 못하더라도, 나중에 다시 읽을 수 있다.
(혹여나 잘못된 정보가 있거나 누락된 부분이 있다면 댓글달아주시면 감사하겠습니다.)
참고
도서 : 실전 카프카 개발부터 운영까지
[Apache Kafka] 카프카란 무엇인가?
카프카, 데이터 플랫폼의 최강자 책을 공부하며 쓴 정리 글 입니다.카프카(Kafka)는 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 설계된 고성능 분산 이벤트
velog.io
https://ssnotebook.tistory.com/entry/Kafka-Kafka%EA%B0%80-%EB%B9%A0%EB%A5%B8-%EC%9D%B4%EC%9C%A0
[Kafka] Kafka가 빠른 이유
kafka 홈페이지 : https://kafka.apache.org/ Apache Kafka Apache Kafka: A Distributed Streaming Platform. kafka.apache.org Apache Kafka는 최근 많은 회사에서 데이터 파이프라인의 중추적인 플랫폼으로 채택되어 이용되고 있
ssnotebook.tistory.com
https://deep-jin.tistory.com/entry/apache-kafka
[Kafka] 카프카 주요 개념 정리
Apache Kafka는 분산 메시징 시스템(A high-throuhput distributed messaging system)이다. 2011년 링크드인에서 처음 개발 됐다. 자사 웹사이트의 이벤트 체크 목적으로 만들어지기 시작했고 2014년 아파치 재단으
deep-jin.tistory.com
[카프카] 용어 정리🔍
회사에서 IOT 데이터를 스트리밍하기 위하여 Kafka를 사용하고 있다.DevOps Engineer로서 운영 관점에서 Kafka를 잘 사용하는 방법을 공부하고자 카프카 시리즈를 시작한다!첫 게시물이니카프카의 아주
velog.io
[kafka/Docker] 도커로 카프카를 띄워보고, 토픽 생성 후 메시지를 보내보자.
카프카란? 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼이다. 즉, API로 데이터를 바로 요청을 하는 것이 아닌 미들웨어인 카프카를 둬서 프로듀
9hyuk9.tistory.com
https://dkswnkk.tistory.com/705
Kafka 개념과 Spring Boot + Kafka 간단한 연동
서론 기존 데이터 시스템의 구조는 각 애플리케이션과 데이터베이스가 end-to-end로 직접 연결되어 있었습니다. 이러한 구조는 간단하지만 각각의 데이터 파이프라인이 분리되어 있어, 요구사항
dkswnkk.tistory.com
'Back-End' 카테고리의 다른 글
| REST API URI 생성 규칙 (0) | 2024.07.26 |
|---|---|
| 멀티 모듈은 뭘까? (0) | 2024.04.22 |
| HTTP 상태 코드에 대해서 (1) | 2024.04.12 |
| [Spring Boot] 배포 방법 (JAR vs WAR) (0) | 2024.03.21 |
| Gradle 의존성 옵션 종류 (0) | 2024.03.20 |