머신러닝은 주어진 데이터를 바탕으로 스스로 규칙성을 찾아내는 데 집중한다.
발견한 규칙성을 이용해 새로운 데이터가 들어오면 그 규칙에 따라 정답을 예측하려 한다.
머신러닝의 장점
- 많은 수동 조정과 규칙이 필요한 문제에 적합
- 간단한 코드로 효과적인 수행되도록 할 수 있음
- 전통적인 방식으로 해결 방법을 찾기 어려운 복잡한 문제에 적합
- 유동적인 환경
- 새로운 데이터에 빠르게 적응
- 복잡한 문제, 대량의 데이터에서 통찰을 얻을 수 있음
머신러닝의 핵심 도전 과제
- 충분하지 않은 데이터
- 충분히 많은 양의 데이터로 학습해야 정확도가 높게 나옴
- 대표성이 없는 데이터
- 새로운 데이터에도 잘 적용되도록, 학습 데이터는 전체를 대표할 수 있어야 함
- 샘플링 잡음 (sampling noise) : 샘플이 적을 때 우연에 의한 대표성 없는 데이터가 생김
- 샘플링 편향 (sampling bias) : 샘플이 많을 때 매우 큰 샘플도 표본 추출 방법이 잘못되면 대표성을 띄지 못할 수 있음
- 낮은 품질의 데이터
- 에러와 잡음이 많은 데이터는 패턴 학습을 방해하므로, 머신러닝에서는 데이터 정제가 핵심 과정
- 관련 없는 변수
- target 변수와 관련이 높은 변수들을 찾아내는 변수 공학(feature engineering)이 필요
- 변수공학 : 변수선택, 변수추출, 새로운 파생변수 생성
- target 변수와 관련이 높은 변수들을 찾아내는 변수 공학(feature engineering)이 필요
- 데이터 과대적합
- 학습 데이터에만 너무 잘 맞춰져 있어 새로운 데이터에 대해 성능이 떨어지는 현상
- 데이터 과소적합
- 모델이 너무 단순해서 학습 데이터의 패턴조차 제대로 학습하지 못하는 상태
- 해결 방안
- 모델 파라미터가 더 많은 강력한 모델 활용
- 더 좋은 변수들을 활용
- 모델의 제약을 줄임
종류
- decision tree & logistic regression
- 금융, 의료와 같은 정형 데이터에서는 충분한 예측력이 보장될 때, 통계적 설명력이 높은 모델들이 여전히 많이 사용됨
- Gradient boosing 계열 고도화된 알고리즘
- 정형 데이터에서는 예측력 향상을 위해 XGB, LGB, CatGB와 같은 부스팅 계열 모델이 많이 사용됨
평가
- 훈련용 : 모델을 학습하는 용도
- 검증용 : 모델의 성능을 조정하기 위한 용도, 과적합이 되고 있는지 판단, 하이퍼파라미터 조정 용도
- 하이퍼파라미터 : 모델의 성능에 영향을 주는 변수(값)
- 매개변수 : 가중치와 편향, 학습을 하는 동안 값이 계속 변하는 수
- 테스트용 : 학습한 머신 러닝 모델의 성능을 평가하기 위한 용도
분류와 회귀 (y값이 categorical인지 continuous한 값인지에 따라 분류, 회귀가 나뉨)
- 분류
- 이진분류
- 다중 클래스 분류
- ex) One versus the Rest/all, One versus One
- 회귀
학습의 종류
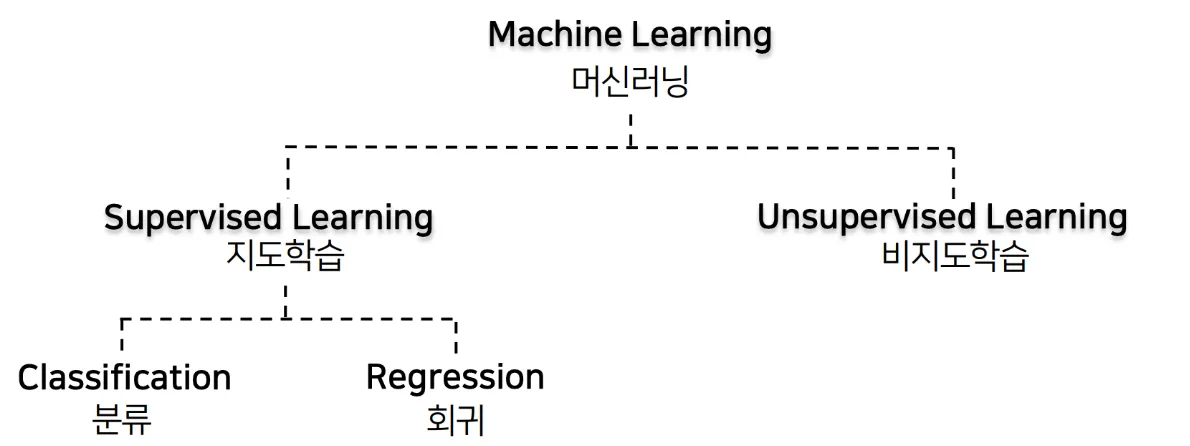
| 구분 | 특징 | 대표 알고리즘/모델 |
| 지도학습 (Supervised Learning) |
입력(X)과 정답(Y, 라벨)이 주어진 상태에서 학습 > 예측,분류 목적 |
- 모수적 모델 - 비모수적 모델 |
| 비지도 학습 (Unsupervised Learning) |
정답(Y)이 없음 데이터의 구조, 관계, 패턴 탐색에 초점 연구자의 주관 개입 여지 큼 |
- 군집화 - 이상치 탐지 - 차원축소, 시각화 - 연관 규칙 학습 |
| 준지도 학습 (Semi-Supervised Learning) |
일부 데이터만 라벨이 있음 라벨링 비용이 큰 현실 문제에 유용 |
- 심층신뢰 신경망 - 제한된 볼츠만 머신 기반 + 지도학습으로 미세 조정 |
| 강화학습 (Reinforcement Learning) |
Agent가 환경과 상호작용하며 보상/벌점 기반으로 최적 정책 학습 |
Q-learning, SARSA, Deep Q-Network (DQN), Policy Gradient 계열 |
| 자기지도학습 (Self-Supervised Learning) |
데이터의 일부를 스스로 라벨링해 학습 최근 딥러닝, 언어모델 핵심 |
Word2Vec, BERT, GPT, SimCLR 등 |
| 배치학습 (Batch Learning) |
가용한 데이터를 한 번에 학습 (Batch Size) 점진적 학습 불가, 자원 소모가 크므로 보통 오프라인에서 수행 (오프라인 학습이라고도 함) |
전통적 ML 모델 대부분 (SVM, 랜덤포레스트 등) |
| 온라인학습 (Online Learning) |
데이터를 순차적으로 (1개 or 미니배치) 학습 실시간, 점진적 학습 가능 시간, 비용 효율적 |
SGD 기반 알고리즘, 온라인 로지스틱 회귀 등 문제점 : 나쁜 데이터 유입 시 성능 저하 > 해결 : 시스템 성능 모니터링, 학습 중지 후 롤백, 이상치 탐지 활용 |
학습시 진행 순서
- 학습 데이터와 테스트 데이터의 분포가 동일한지 여부 파악
- 활용한 모델 알고리즘 선정
- hyperparameter tuning case 정의
- cross validation 기반 학습 진행 (모든 학습 데이터를 학습과 검증에 활용)
- 유의미한 결과가 나오는 알고리즘 및 hyperparameter case를 기반으로 학습데이터 전체 학습
- 테스트 결과 확인