확률통계 기본 정리 & 개념
중심극한정리
- 조건
- 확률변수들이 서로 독립일 것
- 동일한 분포 (또는 일정한 평균과 분산을 가진 분포)에서 나올 것
- 각 확률변수의 평균은 μ, 분산은 σ^2
- 의미
- 모집단의 분포 형태가 어떻든 상관없이, 표본평균은 정규분포를 따른다.
- 즉, 정규분포는 통계학에서 강력한 도구, 여러 통계적 추론의 기반이 된다.
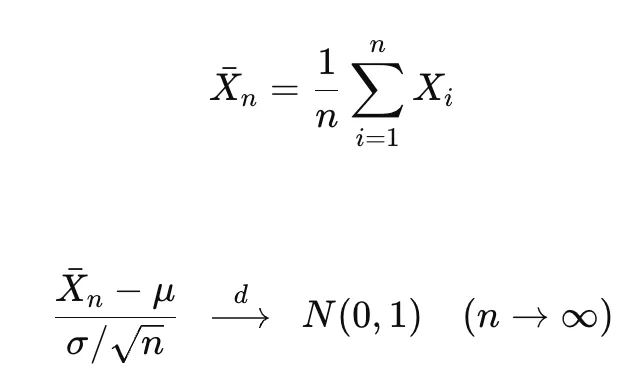
> 중심극한정리란, 표본이 충분히 크면 어떤 분포에서 왔든지 표본평균은 정규분포를 따른다는 강력한 통계 법칙
> 표준화된 표본평균은 표준정규분포에 수렴한다는 뜻
- 예시
- 원래 데이터 분포가 한쪽으로 치우치거나 꼬리가 긴 분포라 하더라도,
표본 크기를 크게 잡아 표본평균을 여러 번 구하면 그 분포는 점점 정규분포(종 모양)에 가까워짐 - 주사위를 여러 번 굴려 평균을 계산 > 결과 분포는 정규분포에 수렴
- 동전을 여러 번 던져 앞면 비율을 계산 > 그 값들도 정규분포 모양을 닮아감
- 원래 데이터 분포가 한쪽으로 치우치거나 꼬리가 긴 분포라 하더라도,
대수의 법칙
- 의미 및 특징
- 보통 큰 수의 법칙이라고도 불림
- 확률 실험을 반복했을 때 관찰되는 평균값이 이론적 기대값에 점점 가까워진다는 것
- 확률론과 통계학에서 매우 중요한 개념
- 예시
- 동전을 던지면 앞면이 나올 확률은 0.5
- 하지만 10번 던지면 앞면이 5번 나오지 않을 수도 있음
- 그러나, 1000번, 10000번, 100000번 ... 던질수록 앞면이 나올 비율은 0.5에 점점 가까워짐
- 종류
- 약한 대수의 법칙 (Weak Law of Large Numbers, WLLN)
- 표본평균이 확률적으로 기대값에 수렴한다는 의미
- 즉, 큰 수의 법칙은 "확률적으로" 기대값에 가까워진다고 보장
- 강한 대수의 법칙 (Strong Law of Large Numbers, SLLN)
- 표본평균이 "거의 확실한(almost surely)" 기대값에 수렴한다는 의미
- 무한히 많이 반복하면 반드시 기댓값에 수렴한다고 볼 수 있음
- 약한 대수의 법칙 (Weak Law of Large Numbers, WLLN)
편향과 오차
- 편향 (bias)
- 편향된 데이터 : 실제 데이터를 반영하지 못하고 편향된 데이터
- ex) 한 유명한 해외 얼굴데이터 세트는 대부분 서양인 얼굴로 구성되어있음. 이를 가지고 학습하여 한국인을 대상으로 하는 서비스를 만들면?
- 편향이 높을 때 : 모델이 예측한 값이 정답과 멀리 떨어져 있는 경우
- 분산이 높을 때 : 모델이 예측한 값이 서로 멀리 떨어져 있는 경우
- ex) 한 유명한 해외 얼굴데이터 세트는 대부분 서양인 얼굴로 구성되어있음. 이를 가지고 학습하여 한국인을 대상으로 하는 서비스를 만들면?
- 편향된 데이터 : 실제 데이터를 반영하지 못하고 편향된 데이터
- 오차 (error)
- 기계 학습 모델의 성능을 평가하기 위해 오차를 계산하는 과정 필요
- 현재 학습 중인 모델이 얼마나 잘못되었는지 측정할 필요 있음
- 오차 : 실제 정답과 우리 모델이 예측한 값의 차이
- 오차는 내 모델이 얼마나 잘못되었는지 알려주는 수치화된 값
- 비용 또는 손실이라고 불림
회귀분석
회귀 분석? 변수들 사이의 함수적 관계를 탐색하는 개념
오차 vs 잔차
- 비슷한 개념
but, 모집단인 참 회귀식과 실제 데이터의 차이 > 오차
추정된 회귀식과 실제 데이터의 차이 > 잔차
산점도
- 두 변수간의 추세 (선형, 곡선, 패턴없음)
- 방향 : 양, 음, 방향없음
- 강도 : 관계가 얼마나 강한지
공분산
- 두 변수가 얼마나 상관성을 갖는가 (-∞~∞)
- 단점 : 단위에 영향을 크게 받음
- 공분산은 두 변수간의 관계의 방향성을 알려줌
- 그러면 추세나 강도? > 상관계수

상관계수
- 공분산의 단점을 보완하기 위해 공분산을 표준화한 값 (-1~1)
- 관계의 방향 + 추세 + 강도를 알 수 있음
- 다른 공분산끼리 비교 불가능해도 상관계수끼리 비교 가능

선형 회귀

- 단순 선형회귀
- 설명변수와 반응 변수의 산점도를 잘 설명할 수 있는 가장 정확도 높은선
- 참회귀식이 존재한다고 가정하고 가장 비슷한 추정 회귀식을 찾음
- LSE(최소제곱법)
- LSE를 사용하는 이유
- 추정치의 확률분포를 몰라도 사용 가능
- 가우스-마코프 정리에 의해 BLUE(최량선형불편추정량)을 구할 수 있음
- 즉 가우스 마코프 정리에 의해 LSE 추정량은 불편성, 선형성을 가진 추정량 중 최소 분산을 갖는 추정량
- 제곱합을 쓰는 이유
- 미분이 편리하고 오차가 클수록 패널티를 부과하는 효과가 있음
- 음수의 경우 합쳐지면 양수와 더해져 제대로 추정이 어려움
- LSE를 사용하는 이유
